The 5 challenges of an Auto ML implementation
Multiple automl solutions are gaining traction in the open source community, their implementation at scale raises a few challenges
6 min
Apr 25, 2019 from Activeeon

By overcoming the complexity of machine learning models and (even more) deep learning models which are literally full of hyperparameters, Auto ML (automated machine learning) theories are gaining popularity. Indeed, the traditional way of developing a machine learning model is time consuming, requires a lot of trial-and-error and a good knowledge of the domain. Auto ML simplifies the process of identifying the best hyperparameters by selecting a combination that will optimize the model training score. This will give every scientist and researcher a solution to get the best model given the available resources: compute, money, and time.
In short, here is a definition of Auto ML:
With some training data and an objective for the model, automated machine learning is the process of iterating through an exploration space to select the best model based on the training scores. The exploration space is composed of combination of algorithms, feature extraction, hyperparameters selection, etc.
As you may have noticed, generally, there is a large gap between theory and practice. A robust implementation of such Auto ML systems is consequently cumbersome and require overcoming a few challenges.
In this article, we will explore some of the challenges of an Auto ML implementation and provide a solution that could support a smooth implementation.
Parallelization and optimal resource utilization
At scale, you must be concerned by resource utilization since the bill can quickly go up whether you are on-prem with expensive GPUs or in the cloud. Fortunately, the main objective of Auto ML solutions is to identify the best set of hyperparameters for your model. It is consequently possible to select multiple sets of those parameters and train models in parallel and maximize utilization.
The theory seems simple but raises more technical challenges such as:
- How to connect to all those machines? Do I need to contact IT and make a request?
- How to move my local Jupyter script on all those machines?
- How to quickly identify issues and manage errors?
- How to quickly replicate my training process over multiple and heterogeneous infrastructures?
In addition, you would also need a solution that integrates as much as possible within the data scientist environment.
Our approach at Activeeon is to provide a complete scheduling solution with a workflow/pipeline system and a resource manager. With the ProActive AI Orchestration solution, data scientists can quickly create structured workflows from Python SDKs, Jupyter Notebooks (through Proactive Kernel) or directly in a studio. This enables standardization of the script and ensure compatibility on any system. On another side, a resource manager would abstract away the resource and give data scientists access to compute. Indeed, IT departments could setup connection to on-prem resources, setup elastic cloud resources and more.
As a side note, a workflow system also enables standards in terms of structure and could benefit data scientists with reusable code or pipelines. For instance, some systems could be in place to stop model training when the loss value increases.
Result collection and analysis
Now that we went through the parallelization of training, the goal is to collect and visualize all the tests and their results. To be more precise, you have to collect the various combinations of algorithms and feature selections and associate the training scores.
Again, the implementation of this collection and visualization system would not be that complex but is time consuming to implement and maintain:
- Which database to choose?
- How to connect?
- Which solution to use for data visualization?
Our approach was to integrate within the scheduling solution a native micro service to export parameters with a single line of code. With that approach, just focus on your algorithm and export relevant value on what we call result map. The results can then be extracted easily and used by the Auto ML algorithms.
In addition to the actual Auto ML system detailed above, we’ve built a dashboard to visualize those results (input and output). This could then be used to identify correlation between hyperparameters and results such as loss value or prediction accuracy.
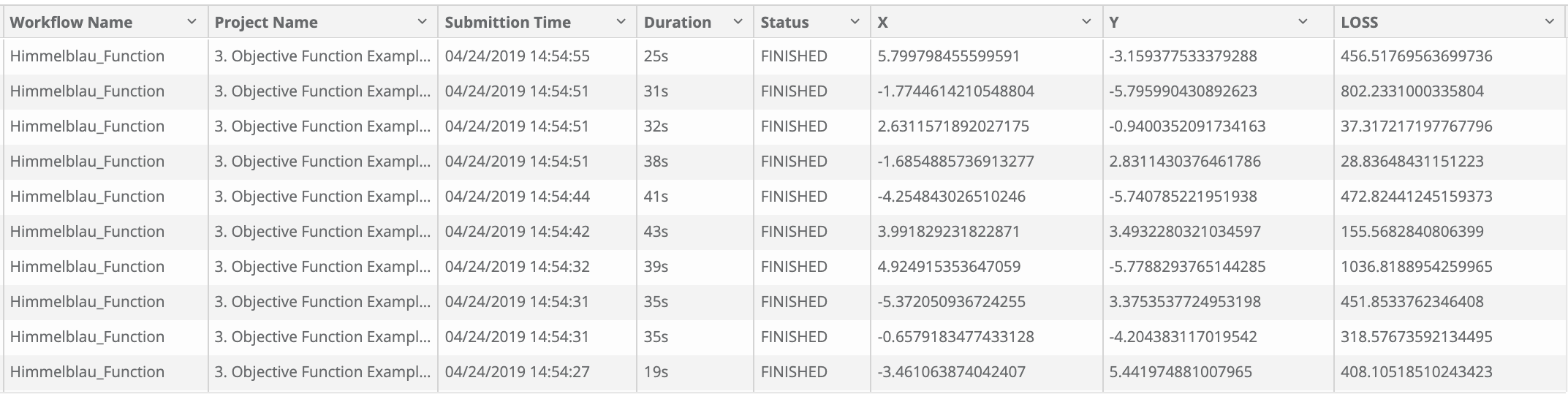
You could also request to visualize the input variables, here X and Y.
And visualize the output with those parameters.
Hyperparameter creation
Now let’s tackle the core of Auto ML systems, the creation of combinations of algorithms, feature selections and hyperparameters. As mentioned above, we’ve implemented a solution to easily extract all the previous tests and their results. The main challenges were to identify the libraries that would support our distributed approach.
No need to go to much in detail in this section, multiple articles have been published on algorithm selection. We wanted to quickly present our comparative analysis of various hyperparameter algorithms used for Auto ML that we’ve studied.
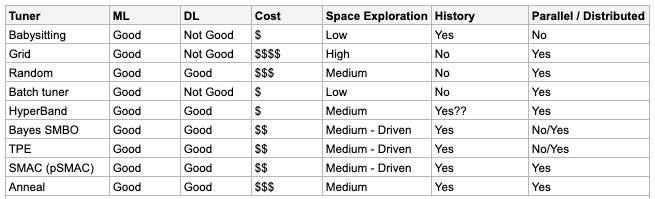
You can obviously integrate your own hyperparameter algorithm for Auto ML if the one provided does not suit your use case or current processes.
Stopping early and precision
On the previous section we’ve talked about the main components for a complete Auto ML system, the next challenge is to set a limit. Depending on the research space specified, there could be unlimited options to try.
Obviously, there are multiple choices on when to complete and stop the training that depends on your objectives and your available resources. Our approach is to focus on three most common patterns:
- Stop the Auto ML system when the accuracy expected is met
- Stop the Auto ML system when the loss value is increasing
- Stop the Auto ML system when after a set of iterations
- Stop one iteration when the accuracy of after each epoch is not improving to avoid wasting resources
Within the solution, we provide a few pipeline templates to follow and use in order to quickly setup the most relevant strategy for your situation.
Pipeline and iteration
Finally, you will need to create a complete pipeline from feature extraction, automated selection of algorithms and hyperparameters, collection of the results and feeding it back to the auto ml algorithm for a new batch. This also includes the distribution of the workload over available and relevant resources such as CPUs, GPUs, FPGAs, or TPUs. Indeed, searching for the best hyperparameters is an iterative process constrained by compute, money and time.
At that stage, the challenges become more related to operation and industrialization. Multiple requirements are critical such as:
- The ability to quickly represent a pipeline through workflows
- The ability to handle software or hardware errors without impacting the complete process
- The ability to collect logs from various servers
- And more
On those aspects, scheduling and workload automation solutions have already invested a lot in developing features for governance of running processes. Those features are already included and can benefit data scientists and IT departments. No additional tracking or effort is required from the data scientists to become compliant with IT rules and meet high standards.
Conclusion
In conclusion, Auto ML implementation is raising a few challenges such as parallelization, result collection, resource optimization, iteration, etc. Machine learning pipelines provide a solution to answer those challenges with a clear definition of the process and automation features. It is then possible to achieve consistency, reliability, scalability and portability.
In a few words, ProActive AI Orchestration from Activeeon, provides an open source workflow/pipeline solution that enables data scientists and companies to quickly take advantage of auto ml concepts and accelerate the model training.
Do you have any challenge that haven’t been explored in this article that you would like us to detail? Let us know in the comments.
With the contribution of our Machine Learning team: Andrews Sobral, Imen Bizid, Caroline Pacheco