Livre blanc - 2019
Aujourd’hui, nous sommes inondés de données. Avec la croissance rapide des applications d’analyse des réseaux sociaux, d’analyse sémantique sur le web, d’analyse de la bioinformation, l’intelligence artificielle, l’Internet des Objets, une grande quantité de données doit être traitée pour améliorer la précision et créer une valeur. Par exemple : Google traite plus de 24 Pétaoctets de données chaque jour (mille fois le volume de toutes les publications de la Bibliothèque nationale américaine); plus de 10 millions de photos et 3 milliards de “likes” sont ajoutés par jour sur Facebook; YouTube attire jusqu’à 800 millions de visiteurs par mois; le contenu de Twitter double chaque année, etc.
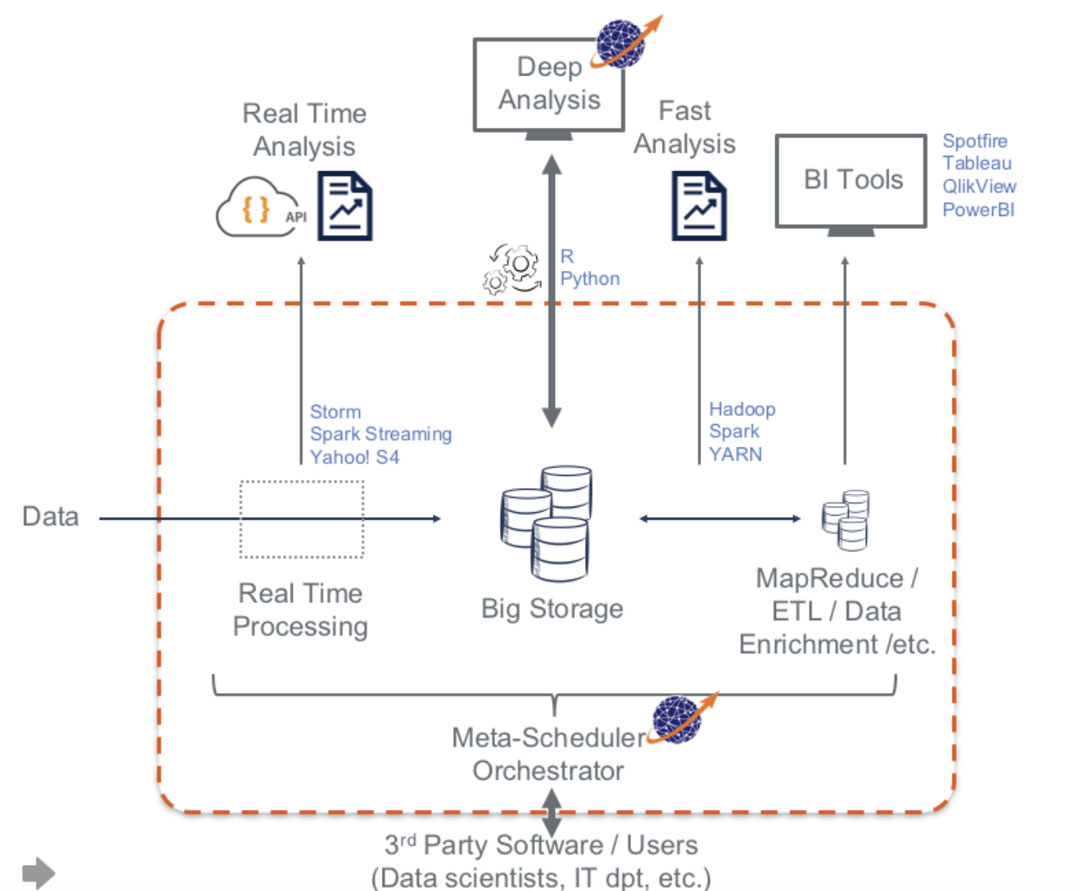
Par conséquent, le traitement du big data crée divers défis à différents moments du cheminement de ces données. Certaines informations doivent être extraites dès que les données sont créées, tandis que d’autres peuvent nécessiter un ensemble plus large de données pour avoir un sens. Même si de nombreuses solutions ont leur propre ordonnanceur et gestionnaire de ressources, pour organiser toutes ces activités et optimiser la parallélisation des traitements, un orchestrateur ou méta-ordonnanceur complet avec capacité de workflow est généralement nécessaire.
Nous reviendrons sur ces aspects de l’orchestration à la fin de notre livre blanc, commençons d’abord par présenter les différents types de traitement de données parallèles utilisés pour le big data.
Téléchargez le livre blanc