Whitepaper - 2018
Storing, processing and extracting value from the data are becoming IT department’s’ main focus. The huge amount of data, or as it is called Big Data, have four properties: Volume, Variety, Value and Velocity. Systems such as Hadoop, Spark, Storm, etc. are de facto the main building blocks for Big Data architectures (e.g. data lakes), but are fulfilling only part of the requirements.
Moreover, in addition to this mix of features which represents a challenge for businesses, new opportunities will add even more complexity. Companies are now looking at integrating even more sources of data, at breaking silos (variety is increasing with structured and unstructured data), and at real-time and actionable data. All those are becoming key for decision makers.
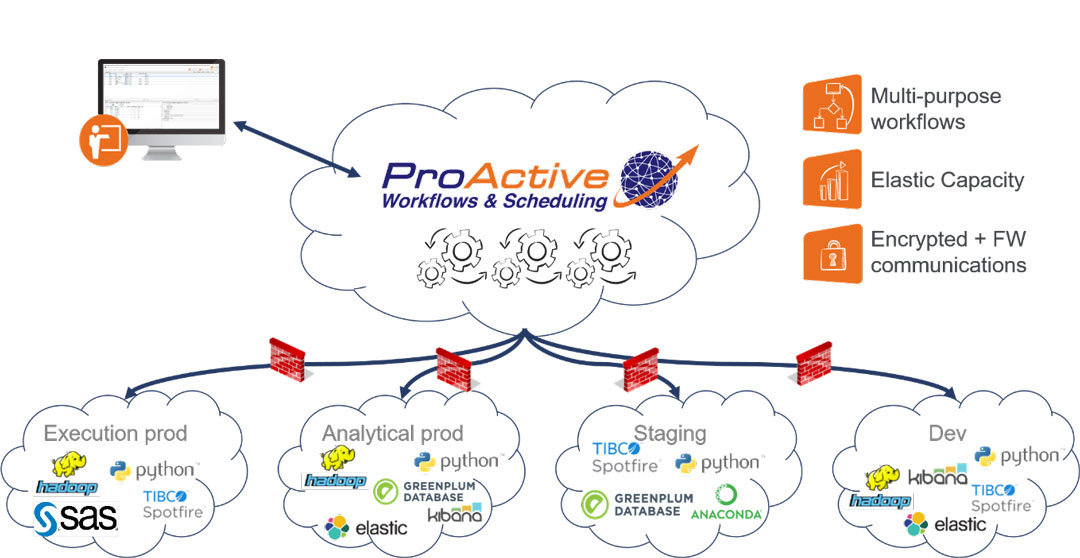
To organize all of these solutions and optimize parallelization, an orchestrator or meta-scheduler is required. This will pilot diverse applications to ensure the process flow is respected, ensure the data follow government and company policies (e.g. data location), handle error management and ensure full integration with other solutions such as BI tools, reports, etc. Moreover, to overcome challenges faced by each individual solution, orchestrators enable secured data transfers, enable resource selection through firewalls, balance the overall load efficiently, etc.
Get the whitepaper written by our team to learn more about how to orchestrate big data from different sources and applications in your organization.